从零开始的Rust
Quote参考资料:
- Video: Rust编程语言入门教程(Rust语言/Rust权威指南配套)【已完结】
- Cookbook: Rust 程序设计语言
Summary
- 这是一篇长文,记录我一步一步从零开始学习 Rust 的过程和一些思考,这篇文章会持续更新~
- 此外,由于我之前学习过一点 C 语言、Python 和 Java,因此文章中我可能会从其他语言的角度解释 Rust,以便更好理解 Rust 的特性
通用编程规范
变量与常量
变量分为两种:不可变变量和可变变量
- 不可变变量
fn main() {
let x = String::from("hello world");
println!("{}", x);
}
上面的 x 就是不可变变量,如果对不可变变量进行赋值就会出错:
fn main() {
let x = String::from("hello world");
x = String::from("test") // error: cannot assign twice to immutable variable
}
- 可变变量
fn main() {
let mut x = String::from("hello world");
println!("{}", x);
x = String::from("test");
println!("{}", x);
}
上面的 x 就是可变变量,x 经历了两次赋值

我觉得常量与不可变的变量最大的一个区别就是:变量的初始化是在程序运行时动态完成的,但常量的初始化是在编译阶段写死在代码中的
shadowing
在 Rust 中,每个变量的值和变量名都是一一对应的,因此通过覆写的方法可以修改变量的数据类型
fn main() {
let x = 1;
println!("the value of x is {}", x);
let mut x: u32 = x + 1;
println!("the value of x is {}", x);
x = x+2;
println!("the value of x is {}", x);
}
程序:猜数游戏
Rust 是一个强类型静态语言,意味着要想运行它需要先进行编译,可以使用命令 rustc filename.rs 编译 Rust 源代码,通过 ./filename 运行编译好的程序。
但这种方式仅适用于简单的源文件编译,Rust 中使用 cargo 来对项目进行管理,cargo new project_name 可以创建一个 Rust 工程项目,这个工程项目包含源代码、目标程序、cargo 配置项三个部分,并使用 git 工具进行版本管理
[package]
name = "rust_playground"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
rand = "0.8.5"
use std::cmp::Ordering; // prelude
use std::io; // prelude
use rand::Rng; // trait
fn main() {
println!("Welcome to the guessing game!");
let secret_num = rand::thread_rng().gen_range(0..101);
loop {
let mut guess = String::new();
println!("Please guess a number!");
io::stdin().read_line(&mut guess).expect("wrong number!");
let guess:i32 = match guess.trim().parse() {
Ok(val) => val,
Err(_) => continue,
};
match guess.cmp(&secret_num) {
Ordering::Greater => println!("Too big!"),
Ordering::Less => println!("Too small!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}
在 Rust 中,程序首先会导入一些标准库,这些标准库就称为 prelude,它可以保证你使用一些简单的数据结构和标准的输入输出等功能。
引入的各种 Rust 包通过 cargo.toml 进行管理,暴露的接口被称为 trait,cargo 包管理机制如下:
cargo.toml文件中引入的包无法直接使用,需要进行cargo build,并将具体的版本信息写入cargo.lock中(cargo.lock中的包版本可能会和cargo.toml声明的不一致,因为 cargo 会自动选择当前大版本中的最新小版本写入cargo.lock中)- 在下次
cargo build时会直接调用cargo.lock中的包,从而保证包的版本一致性 - 当我们打算更新 cargo 包时,我们使用
cargo update来更新,cargo 会自动重新计算依赖关系
Ownership *(所有权)
所有权是 Rust 的核心,它让 Rust 无需垃圾回收就可以轻松管理堆内存
内存管理的方式有很多,类似 java 就是把垃圾管理机制放在运行过程中,由 GC 自动进行垃圾回收;或者类似 c++,需要程序员手动进行内存申请和释放,极大增加了心智负担;对比上面两种主流方式,可以发现,GC 可以减少程序员管理内存的压力,但是会提高内存需求,自行管理内存虽然简洁明了,但常常会出现野指针、内存溢出等尴尬情况,Rust 为了解决这个问题,引入了所有权概念,使得其在编译阶段就完成了对内存的管理,且保证了程序运行的安全
Attention在深入了解所有权之前,请牢记所有权规则:
- Rust 中的每一个值都有一个 所有者(owner)
- 值在任一时刻有且只有一个所有者
- 当所有者(变量)离开作用域,这个值将被 drop
fn main() {
{
let s = String::from("hello world");
println!("{}", s);
}
println!("{}", s); //error
}
String 类型的分配是一个典型的堆分配方式,上面这段代码,会在编译时报错,因为它没有遵循所有权规则,尝试调用一个在作用域外的变量,所以失败了;变量在作用域结束时会自动调用 drop 函数,将分配的内存还给分配器
fn main() {
let s1 = String::from("hello world");
let s2 = s1;
println!("{}", s1); //error
}
上面的代码阐述了另一个可能遇到的问题,在执行 let s2 = s1 这段代码时,需要考虑其采用的是深拷贝还是浅拷贝,在深拷贝情况下,实际上是重新开辟了一段内存给 s2 并将 s1 的值进行 copy,但在 Rust 中 let s2 = s1 执行的是浅拷贝,因此只是移动了指针的指向 *s2->s1,如果依然采用上述内存回收方法,在释放时会进行二次释放,即 drop 函数会释放 s1 和 s2 内存,但 s2 的内存已经释放过一次了
所以在 Rust 中,上述情况 s1 不再具有字符串的所有权,而是转移给了 s2
fn main() {
let s = String::from("hello world");
take_ownership(s);
println!("{}", s); //error
}
fn take_ownership(s: String) {
println!("{}", s);
}
如果变量被当作参数传入函数中,其实也是一次 赋值 操作,因此 main函数 中变量 s 的所有权被 take_ownership 中的参数 s “夺走”,main 函数中的变量 s 失效!
聪明的你一定想到了一种转移所有权的方法:
fn main() {
let mut s = String::from("hello world");
s = take_ownership(s);
println!("{}", s);
}
fn take_ownership(s: String) -> String {
println!("{}", s);
s
}
是的,你可以通过返回值进行转移了,但是有一个很傻逼的点,如果你需要返回其它参数的话,你就需要进行解构:
fn main() {
let s = String::from("hello world");
let (s, ss) = take_ownership(s);
println!("{}", s);
println!("{}", ss);
}
fn take_ownership(s: String) -> (String, String) {
let ss = String::from("bye world");
println!("{}", s);
(s, ss)
}
为了解决上面的问题,我们可以使用 Rust 的另一个特性:引用
引用与借用
引用这一特性对我来说并不陌生,在学习 C 语言数据结构时就已经见过了"引用"这一特性,并且原书中说只是为了简化操作而引入的一种特性(简化了操作指针,可以直接把引用当作变量进行操作,如果用指针则还需要进行取值 (*p) 操作),Rust 具体操作如下:
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{s1}' is {len}");
}
fn calculate_length(s: &str) -> usize {
s.len()
}
需要注意的是它们的引用关系是这样的:
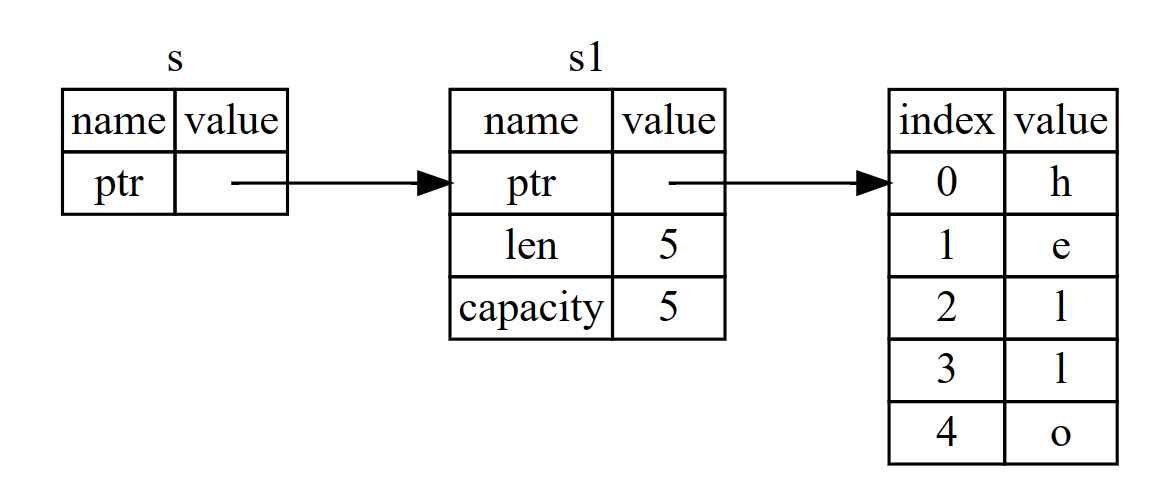
在函数定义中,我们获取 &String 而不是 String。这些 & 符号就是 引用,它们允许你使用值但不获取其所有权
我们将创建一个引用的行为称为 借用(borrowing)。正如现实生活中,如果一个人拥有某样东西,你可以从他那里借来。当你使用完毕,必须还回去。我们并不拥有它
可变变量引用
在使用引用时,在对可变变量进行引用时需要注意避免数据竞争,不能同时声明 2 个/以上对同一可变变量的引用
Attention引起数据竞争存在三个条件:
- 两个或更多指针同时访问同一数据
- 至少有一个指针被用来写入数据
- 没有同步数据访问的机制 当三个条件都满足时,就会产生数据竞争
fn main() {
let mut s = String::from("hello world");
let s1 = &mut s;
let s2 = &mut s;
println!("{}, {}", s1, s2); // error
}
上述代码中,s1 和 s2 都是可变变量 s 的引用,违反数据竞争,因此报错
悬垂引用
考虑一种情况,如果指针指向的内存被释放,那么指针就会成为"悬垂引用"(C 语言里叫做野指针),这就会发生一系列可能出现的问题,这对于程序来说是不安全的,在 Rust 中,我们可以在编译时期就避免这个问题出现,当你拥有一些数据的引用,编译器确保数据不会在其引用之前离开作用域
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello"); // dangle结束内存就会被释放
&s
}
上面的代码是会直接报错了,因为不允许将借用的值作为返回值,这样如果作用域在 dangle 函数外,reference_to_nothing 变量就会成为一个野指针
切片 slice
切片是 Rust 的另外一种不持有所有权的数据类型
use std::io;
fn main() {
println!("Please input a word:");
let mut sentence = String::new();
io::stdin().read_line(&mut sentence).expect("wrong word!");
let first_word_idx = first_word(&sentence);
println!("The length of first word is {first_word_idx}");
}
fn first_word(s: &str)->usize{
let bytes = s.trim().as_bytes();
for(i, &item) in bytes.iter().enumerate(){
if item == b' ' {
return i;
}
}
s.len()
}
在上面这个例子中,我们创建了一个 first_word 方法,能够返回字符串第一个单词的长度,但这里会有一个 bug:如果我们在后面代码中把 sentence 的内容清空,first_word_idx 就无效了!它会指向一个错误的地址!
为了解决上述的问题,我们需要使用字符串切片功能
- 形式:
[start_index..end_index]- 开始索引就是切片的起始位置的索引值
- 结束索引就是切片的结束位置的下一个索引值
- 类型:
&str(比&String好用,同时可以接受字符串和切片类型) - 本质:切片保留了开始指针和长度,实际上是对变量的一种借用
fn main() {
let s = String::from("hello world");
let hello = &s[0..5]; // 也可以写成&s[..5]
let world = &s[6..11]; // 也可以写成&s[6..]
let whole = &s[..];
println!("The original s is '{s}'");
println!("The 0..5 of s is '{hello}'");
println!("The 6..11 of s is '{world}'");
println!("The whole of s is '{whole}'");
}
Note给我感觉有点像 python 里的 slice 用法,不过要注意使用切片需要添加
&符号,且这种切片只支持 utf-8 类型
于是之前的第一个单词程序可以被覆写为:
use std::io;
fn main() {
println!("Please input a word:");
let mut sentence = String::new();
io::stdin().read_line(&mut sentence).expect("wrong word!");
let first_word_idx = first_word(&sentence);
sentence.clear(); // error
println!("The length of first word is {first_word_idx}");
}
fn first_word(s: &str)->&str{
let bytes = s.trim().as_bytes();
for(i, &item) in bytes.iter().enumerate(){
if item == b' ' {
return &s[..i];
}
}
&s[..]
}
这时如果执行 sentence.clear() 就会报错编译失败,因为数据在变为不可变变量后无法再变为可变变量
Help这里需要详细讲解这个过程,我第一遍看得时候直接懵了,直呼 Rust 牛逼!
- 首先,调用
first_word函数并传入sentence变量和之前一样- 不一样的地方在于,之前返回值是
usize类型,这是一个无符号整型,此时sentence还是可变变量类型;- 而之后的改进版返回的是
sentence切片,这时sentence直接转换为不可变变量(从可变变量转为不可变变量,之后不能再转为可变变量了),从而导致代码编译报错(使用切片,变量和切片就绑定了!)
Struct(结构体)
有点像 C 语言 里的结构体概念,主要用于自定义的数据类型,为相关联的值命名,打包 有意义的组合
初始化操作
/*声明时需要包含:字段名称+类型*/
struct User{
username: String,
age: u32,
email: String,
state: bool,
}
fn main() {
// 初始化实例
let user = User{
age: 18,
username: String::from("odd"),
email: String::from("odd@hello.com"),
state: false,
};
//
println!("{}", user.age); // 取值
user.username = String::from("xiaoxu"); // 赋值
}
Caution
- 实例的属性不可缺失,没有默认值
- 一旦 struct 是可变的,那么所有字段都是可变的(只能是整体可变或不可变,不能部分字段可变,部分字段不可变)
struct User{
username: String,
age: u32,
email: String,
state: bool,
}
fn main() {
let user = build_user(String::from("hello world"), String::from("123@over.com"));
print!("{}", user.username);
}
fn build_user(username: String, email: String)->User{
let user = User{
age: 18,
username, // 简写
email: email,
state: false,
};
user
}
在函数里可以这样使用 struct ,去构造一个结构体实例
struct User {
username: String,
age: u32,
email: String,
state: bool,
}
fn main() {
let u1 = User {
age: 18,
username: String::from("odd"),
email: String::from("email@example.com"),
state: false,
};
// 更新一个结构体
let u2 = User{
age: 30,
state: true,
..u1 // 其他的值直接继承自u1
};
}
Tuple struct
类似 tuple 的 struct,适用于:想给整个 tuple 起名,并让它不同于其它 tuple,而且又不需要给每个元素起名
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
fn main() {
// 虽然上面定义的两个tuple的字段类型都一致,
// 但是两者的实例不同,一个是Color的数组结构体,
// 一个是Point的数组结构体
let c = Color(0, 0, 0);
let p = Point(0, 0, 0);
}
还有一种 unit-like struct,适用于:需要在某个类型上实现某个 trait,但里面又没有想要存储的数据(现在感觉用不上)
Struct 数据的所有权
其实在学完了之前的内容时,我疑惑一个小点:
struct User{
username: String, // 为什么不能用&str
age: u32,
email: String, // 为什么不能用&str
state: bool,
}
String类型为什么不能用切片&str来表示呢?- 该 struct 实例必须拥有其所有数据,否则,如果是借用来的,如何保证不会出现野指针现象呢?(除非一直不可变)
- 当然,struct 里也可以存放引用,但需要引入
生命周期的概念(还没学),如果没使用生命周期则会报错
Struct 使用案例
#[derive(Debug)] // 这是一个注解
struct Rectangle{
width: f32,
length: f32,
}
fn main() {
let rect = Rectangle{
width: 30.0,
length: 60.0,
};
let area = calculate_area(&rect);
println!("{}", area);
println!("{:#?}", rect); // 也可以用{:?}
}
fn calculate_area(rect: &Rectangle)->f32{ // 需要借用,后面在main函数还要输出
rect.width*rect.length
}
Question在这段代码中实现了一个计算长方形面积的函数,为了提高代码的可读性,我创建了一个
Rectangle结构体,但是却无法打印出rect值,因为rect是一个结构体,默认没有实现Display的trait,为了解决这个问题,我又引入了一个注解#[derive (Debug)],它可以让结构体Rectangle继承Debug的trait,因而可以在"{:#?}"中打印出结果
#[derive(Debug)]
struct Rectangle{
width: f32,
length: f32,
}
fn main() {
let scale = 2.0;
let rect = Rectangle{
width: dbg!(30.0*scale), // 这里直接返回所有权
length: 60.0,
};
dbg!(&rect); // 这里我们不希望dbg获取所有权,因此需要借用rect
}
在上面这段代码中,使用了 dbg! 宏定义来打印部分值,dbg! 会获取表达式的所有权,而 print! 只获取值的引用
Attention
dbg!需要自行实现Debugtrait,它只适用于在调试的地方调用,作用有点像print!的调试版dbg!输出到stderr,而print!输出到stdout
Struct 里的方法/函数
Method (方法)
在之前的学习中,我已经接触了 Function(函数)的用法,它是以 fn 关键字开头,并可以传入参数的代码组合,不过函数只能单独声明
而本章要讲的方法,可以被定义在 struct、enum 和 trait 的内部,并且像 Python 一样,它们永远都有一个默认参数 self,表示被调用的实例本身
#[derive(Debug)]
struct Rectangle{
width: f32,
length: f32,
}
impl Rectangle { // 通过实现Rectangle结构体进行方法声明
fn area(self) -> f32 {
self.width*self.length
}
}
fn main() {
let rect = Rectangle{
width: 30.0,
length: 60.0,
};
// 下面两者对调就会报错!
dbg!(&rect);
println!("The area of this Rectangle is {}", rect.area())
}
Caution在声明方法的参数里,可以填
self/&self/&mut self,分别表示所有权剥夺和借用,因此如果想让上面的对调不报错,需要传入&self,如果想要改变实例可以使用&mut self
Note这里的
self必不可少,在 C 语言中,实例变量和指针变量对结构体内容的调用是不同的,需要使用.或->连接,而在 Rust 中没有->操作,这是因为 self 在给定时就已经规定了是所有/借用操作了!
Associated function (关联函数)
如果在定义方法时不传入 self 参数,那么这个方法就叫作关联函数,例如:String::from() 就是一个关联函数(有点类似 python 中的静态方法),主要用于创建构造器
#[derive(Debug)]
struct Rectangle{
width: f32,
length: f32,
}
impl Rectangle {
fn square(size: f32) -> Rectangle {
Rectangle{
width: size,
length: size
}
}
}
fn main() {
let square = Rectangle::square(60.0); // 注意这里调用的时候需要使用::
println!("{:?}", square);
}
Note
::符号除了可以调用关联函数,还可以给模块创建命名空间
除此之外,也可以多次声明 impl
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
Enum 枚举
枚举允许我们列举所有可能的值来定义一个类型
例如在计算机网络中,我们可以有 IPv4 和 IPv6 两种不同的类型,我们可以定义为:
enum IpAddrKind{
V4,
V6
}
使用也很简单:
enum IpAddrKind{
V4,
V6
}
fn main() {
let network1 = IpAddrKind::V4;
let network2 = IpAddrKind::V6;
route(network1);
route(network2);
}
fn route(ip_kind: IpAddrKind){}
当然,还可以作为结构体的内部类型:
enum IpAddrKind{
V4,
V6
}
struct Network{
kind: IpAddrKind,
address: String
}
fn main() {
let local_network = Network{
kind: IpAddrKind::V4,
address: String::from("127.0.0.1"),
};
let loop_network = Network{
kind: IpAddrKind::V6,
address: String::from("::1"),
};
}
枚举也可以拥有数据,例如上面的数据可以简化为:
enum IpAddrKind{
V4(u8, u8, u8, u8),
V6(String)
}
fn main() {
let local_network = IpAddrKind::V4(127, 0, 0, 1);
let loop_network = IpAddrKind::V6(String::from("::1"));
}
Note在枚举中嵌入数据有以下好处:
- 不需要额外使用 struct 定义简单类型
- 每个枚举变体可以拥有不同的类型和关联的数据量
是的,枚举也可以有方法:
enum IpAddrKind{
V4(u8, u8, u8, u8),
V6(String)
}
impl IpAddrKind {
fn connect(&self){
println!("hello world");
}
}
fn main() {
let local_network = IpAddrKind::V4(127, 0, 0, 1);
local_network.connect();
}
Option 枚举
Option 枚举定义于标准库的 Prelude 模块中(默认就可以直接使用),它描述了某个值可能存在(某种类型)或不存在的情况
Note需要注意的是,Rust 没有 Null 类型。在其他语言中,
- Null 是一个值,它表示为空
- 一个变量可以简单分为两种状态:空值(Null)和非空 但从现在的角度来看,有 Null 并不是一件好事,因为它允许开发者引入 Null,如果你将空值像非空值一样使用时,这就会导致空指针异常的产生,这显然不利于程序的内存安全,你可能需要额外的代码处理 Null 的问题(或者你根本不知道你产生了Null)
在 Rust 中,作者引入了 Option<T> 的概念,标准库中的定义是:
pub enum Option<T> {
/// No value.
#[lang = "None"]
#[stable(feature = "rust1", since = "1.0.0")]
None,
/// Some value of type `T`.
#[lang = "Some"]
#[stable(feature = "rust1", since = "1.0.0")]
Some(#[stable(feature = "rust1", since = "1.0.0")] T),
}
即,包含了 None 和 Some 两个变量,在使用时,可以这样写:
fn main() {
// 在下面的代码中,some表示可能有值也可能没有值
let some_num = Some(13); // 声明一个i32类型Some变体
let some_str = Some("hello world"); // 声明一个&str类型Some变体
let unknow_num: Option<i32> = None; // 声明一个i32类型None变体,需要手动指定类型
let certain_num = 12;
let certain_num = certain_num + some_num; // 报错
}
Note这种方式的好处在于:
- Null 安全, T 类型和 Option<T>类型是不同类型,不可以把 Option<T>当成 T
- 若想使用 Option<T>中的 T,必须要进行转换 这迫使开发者在开始就意识到了 Null 存在的可能性,并且及时处理,保证了内存的安全
Match
match 是一个强大的控制流运算符,有点像 C 语言里的 switch case,对不同的情况执行不同的操作,例如下面这种匹配不同枚举的例子:
enum Coin {
Penny,
Nickel,
Dime,
Quarter,
}
fn main(){
let val = value_in_cents(Coin::Penny);
println!("The coin is {val}");
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => 1,
Coin::Nickel => {
println!("This is Nickel!");
5
}, // 如果是函数可以这么使用
Coin::Dime => 10,
Coin::Quarter => 25,
}
}
当然,除了简单的枚举类型,也可以使用带绑定值的枚举类型
#[derive(Debug)]
enum UsState {
Alabama,
Alaska,
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => 1,
Coin::Nickel => {
println!("This is Nickel!");
5
}
Coin::Dime => 10,
Coin::Quarter(state) => {
println!("State quarter from {:?}", state);
25
}
}
}
fn main() {
let c = Coin::Quarter(UsState::Alaska);
println!("{}", value_in_cents(c));
}
同样,Option<T>也是可以直接使用的:
fn main() {
let num1 = Some(5);
let num2 = plus_one(num1);
let num3 = plus_one(None);
println!("{:?}", num2);
println!("{:?}", num3);
}
fn plus_one(x: Option<i32>)->Option<i32>{
match x {
Some(i) => Some(i+1),
None => None,
}
}
Caution使用
match关键字进行匹配时,需要补全所有可能的情况
enum NumType {
Float(f32),
Integer(i32),
NotANum,
}
fn main() {
let num = NumType::Integer(32);
change_value(&num);
}
fn change_value(val: &NumType) -> i32 {
match val {
NumType::Float(_) => {
println!("This is Float");
0
}
NumType::Integer(i) => *i,
_ => -1,
}
}
Note
_是一个通配符,可以代替其他没列出的值或是没使用的绑定数据
if let
fn main() {
let num = Some(3);
if let Some(2) = num{
println!("The num is 3");
}else {
println!("The num is not 3");
}
}
除了使用 match,rust 还提供了更简单的使用方式:if let,使用 if let 可以提供简单的判断,仅当条件满足时才运行,否则直接忽略
Note
if let的优点如下:
- 只关心一种匹配情况,而忽略其他匹配
- 更少的代码,更少的缩进,更少的模板代码
- 更像是 match 的语法糖
- 可以搭配
else使用
模块化
NoteRust 的模块系统包括:
- Package:一个 Package 是 Rust 代码的最高级别组织单位。它通常对应一个 Cargo 项目,是你运行
cargo new或cargo init创建的东西。
- Crate:Crate 是 Rust 的编译单位。每次
cargo build都是针对一个 Crate 编译的。可以理解为 Rust 代码编译成的 “产物”。
- Module:让你控制代码的组织、作用域、私有路径
Package 、Crate 和 Module

前面提到,在创建项目时,我们会使用 cargo new project_name 命令来创建 Package,Package 的名称就是 project_name
一个 Package 的结构大概是这样的:
my_package/ ← Package 根目录
- ├── Cargo. toml ← 包的元数据文件
- └── src/
- ├── main. rs ← 默认二进制 Crate
- └── lib. rs ← 可选库 Crate
# 这是Cargo.toml文件
[package]
name = "rust_playground"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
Note然而,在
Cargo. toml中,并没有配置入口文件地址,这是因为:
src/main. rs是默认的 binary crate 的 crate root- crate 名与 package 名相同
如果项目中包含
src/lib.rs,则:
- package 包含一个 library crate
src/lib.rs是 library crate 的 crate root- crate 名与 package 名相同
最后,Cargo 会把 crate root 文件交给 rustc 来构建 binary 或 library
Summary
- 一个 Package 可以有多个 binary crate:
- 文件放在
src/bin目录下- 每个文件是单独的 binary crate 拥有 crate 可以将相关功能组合到一个作用域内,并防止包内的命名冲突,例如在访问
randcrate 时,我们需要访问它的名字rand才能继续调用相关 trait
- Module 的特性如下:
- 在一个 crate 内,将代码进行分组,文件名就是 module 名
- 增加可读性,易于复用
- 控制项目(item)的私有性:public(
pub)、private (默认)
// src/lib.rs
// Module支持嵌套
mod front_of_house{
mod hosting{
fn add_to_waitlist(){}
fn seat_at_table(){}
}
mod serving {
fn take_order(){}
fn servve_order(){}
fn take_payment(){}
}
}
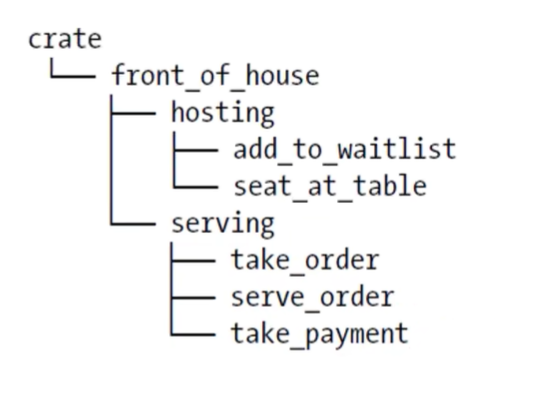
Note
src/main.rs或src/lib.rs中的内容形成了名为 crate 的模块,位于整个模块树的根部
Binary crate 和 Library crate 的区别
crate 是编译器的处理单位,在编译时,一个 crate 可以包含多个 module,但这些 module 可能来自其他文件中,crate 会自动把它们组织起来
binary crate 是一些可执行文件,例如命令行执行、常驻的服务等
library crate 类似工具函数,它们不能直接在命令行运行,但可以给 binary crate 调用
Path(路径)
为了在 Rust 的模块中找到某个条目,需要使用路径。
Summary
- 路径的两种形式:
- 绝对路径:从 crate root 开始,使用 crate 名或字面值 crate
- 相对路径:从当前模块开始,使用
sef,super或当前模块的标识符路径至少由一个标识符组成,标识符之间使用
::
举个
// src/lib.rs
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// crate相当于src/main.rs 或 src/lib.rs
crate::front_of_house::hosting::add_to_waitlist(); // 绝对路径
front_of_house::hosting::add_to_waitlist(); // 相对路径
}
Note在这个例子中,展示了绝对路径和相对路径的调用方法,在实际应用中,如果调用的部分与模块总是一起移动的,那么使用相对路径即可,如果调用的部分总是与模块本身分开,那么就需要使用绝对路径
然而这个例子是错误的,它并不会通过编译,因为默认情况下,在模块内的数据都是 private 的。private 的数据可以在调用时,为使用者隐藏不需要的细节,保证数据安全。官网的例子很详细:private 就像是餐厅里的后厨,一般食客是无法进入的,食客只需要等待菜品上桌即可,厨师的操作对食客是不可见的(食客也不需要知道,只要等菜吃饭即可)
Public and Private
在将模块 hosting 置为 public 后:
// src/lib.rs
mod front_of_house {
pub mod hosting {
fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// crate相当于src/main.rs 或 src/lib.rs
crate::front_of_house::hosting::add_to_waitlist(); // 绝对路径
front_of_house::hosting::add_to_waitlist(); // 相对路径
}
Fail然而,这样还是编译失败,因为虽然
hosting模块已经为 public 但hosting内部仍然是 private 的,所以如果要使用hosting下的add_to_waitlist函数,我们还要将add_to_waitlist设置为 public
super 关键字
// src/lib.rs
fn deliver_order() {}
mod back_of_house {
fn fix_incorrect_order() {
cook_order();
super::deliver_order(); // super表示数据段的上一层
}
fn cook_order() {}
}
super 类似文件系统中的 cd .. 操作,可以直接找到相对的父模块,在上面的例子中,super 的父模块是 crate root
Struct 的 Public
// src/lib.rs
mod back_of_house {
pub struct Breakfast {
pub toast: String,
seasonal_fruit: String,
}
impl Breakfast {
pub fn summer(toast: &str) -> Breakfast {
Breakfast {
toast: String::from(toast),
seasonal_fruit: String::from("peaches"),
}
}
}
}
pub fn eat_at_restaurant() {
// Order a breakfast in the summer with Rye toast
let mut meal = back_of_house::Breakfast::summer("Rye");
// Change our mind about what bread we'd like
meal.toast = String::from("Wheat");
println!("I'd like {} toast please", meal.toast);
// The next line won't compile if we uncomment it; we're not allowed
// to see or modify the seasonal fruit that comes with the meal
// meal.seasonal_fruit = String::from("blueberries");
}
在 struct 中,我们可以对每个字段设置 public(和 Java Bean 有点像,可以有公共字段,也可以有私有字段)
Enum 的 Public
// src/lib.rs
mod back_of_house {
pub enum Appetizer {
Soup,
Salad,
}
}
pub fn eat_at_restaurant() {
let order1 = back_of_house::Appetizer::Soup;
let order2 = back_of_house::Appetizer::Salad;
}
Enum 字段没有 pub 选项,因为显然一个私有 Enum 字段是多余的,如果允许 Enum 字段 private,在使用 match 进行匹配时需要让每个字段都 public 重复操作
use 关键字
use 类似文件系统中的“快捷方式”
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use front_of_house::hosting; // 相对路径和绝对路径都可以
pub fn eat_at_restaurant() {
//如果不用use关键字,就用下面这段语句
//front_of_house::hosting::add_to_waitlist()
hosting::add_to_waitlist();
}
Note
- 使用
use也是需要遵循 private 规则的- 习惯用法:
- 调用函数需要
use到父级模块- 调用 struct,enum 时需要指定完整路径到自身
在创建上面的 library 模块时,我们只能调用 eat_at_restaurant 函数来访问 hosting 模块,hosting 模块本身是不公开的,用户没办法访问到,如果想让 hosting 模块也能被访问,可以使用 pub use 关键字
// src/lib.rs
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
pub use front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}
除此之外,还可以使用嵌套路径多次导入外部包
use std::{self, cmp::Ordering, collections::HashMap, io};
fn main(){}
Note
self表示std::io本身
Attention
- 谨慎使用通配符
*- 应用场景:
- 测试:将所有测试代码引入测试模块
- 有时被用于 prelude 模块
Error Handling 错误处理
-
Rust 中的错误分为两种:
- 可恢复:例如文件未找到,网络未请求成功
- 不可恢复:例如数组访问超出范围
-
Rust 中没有异常机制,因此不能够向上抛出,需要对错误进行及时处理,以保证程序的健壮
- 可恢复错误:
Result<T, E> - 不可恢复:
panic!宏
- 可恢复错误:
用 panic! 处理不可恢复的错误
在实践中有两种方法造成 panic:
- 执行会造成代码 panic 的操作(比如访问超过数组结尾的内容)
- 显式调用
panic!宏
- 当
panic!执行时:- 执行程序会打印一个错误信息
- 展开 (unwind)、清理调用栈 (stack)
- 展开调用栈:
- Rust 沿着调用栈往回走
- 清理每个遇到的函数的数据
- 中止调用栈(二进制文件更小):
- 不进行清理,直接停止
- 程序的内存由 OS 进行清理
- 展开调用栈:
- 退出程序
# 在 `cargo.toml` 文件中可以设置 panic 的默认处理方式
[package]
name = "rust_playground"
version = "0.1.0"
edition = "2021"
[dependencies]
# 可以在这里不同的profile中配置
[profile.release]
panic = 'abort'
// 一个最简单的panic!宏的使用
fn main(){
panic!("this is an error!");
}
在使用一些 Rust 内置方法时也会遇到 panic,例如:
/*
直接报错:
thread 'main' panicked at src/main.rs:3:6:
index out of bounds: the len is 3 but the index is 99
stack backtrace:
0: rust_begin_unwind
at /rustc/eeb90cda1969383f56a2637cbd3037bdf598841c/library/std/src/panicking.rs:665:5
1: core::panicking::panic_fmt
at /rustc/eeb90cda1969383f56a2637cbd3037bdf598841c/library/core/src/panicking.rs:74:14
2: core::panicking::panic_bounds_check
at /rustc/eeb90cda1969383f56a2637cbd3037bdf598841c/library/core/src/panicking.rs:276:5
3: <usize as core::slice::index::SliceIndex<[T]>>::index
at /rustc/eeb90cda1969383f56a2637cbd3037bdf598841c/library/core/src/slice/index.rs:301:10
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
*/
fn main(){
let a = vec![1,2,3];
a[99];
}
可以直接通过回调信息判断错误的具体位置
用 Result 处理可恢复的错误
一些错误是可以恢复的,就像在 try...catch... 的 catch 中可以使用方法恢复错误
// Result结构
enum Result<T, E> {
Ok(T),
Err(E),
}
T 和 E 是泛型类型参数;第十章会详细介绍泛型。现在你需要知道的就是 T 代表成功时返回的 Ok 变体中的数据的类型,而 E 代表失败时返回的 Err 变体中的错误的类型
举一个:
// src/main.rs
use std::fs::File;
fn main() {
let greeting_file_result = File::open("hello.txt");
let greeting_file = match greeting_file_result {
Ok(file) => file,
Err(error) => panic!("Problem opening the file: {error:?}"),
};
}
当然,为了更好地适配错误,我们可以进一步使用 match 划分:
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let greeting_file_result = File::open("hello.txt");
let greeting_file = match greeting_file_result {
Ok(file) => file,
Err(error) => match error.kind() {
ErrorKind::NotFound => match File::create("hello.txt") {
Ok(fc) => fc,
Err(e) => panic!("Problem creating the file: {e:?}"),
},
_ => {
panic!("Problem opening the file: {error:?}");
}
},
};
}
如果 match 对你来说太过冗杂,你也可以使用 闭包 的方案,这样可以解决大量嵌套问题:
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let greeting_file = File::open("hello.txt").unwrap_or_else(|error| {
if error.kind() == ErrorKind::NotFound {
File::create("hello.txt").unwrap_or_else(|error| {
panic!("Problem creating the file: {error:?}");
})
} else {
panic!("Problem opening the file: {error:?}");
}
});
}
如果想在调用失败时直接使用 panic!,就可以使用 unwrap
use std::fs::File;
fn main() {
let greeting_file = File::open("hello.txt").unwrap();
}
expect 提供了一个自定义 panic! 信息的方案
use std::fs::File;
fn main() {
let greeting_file = File::open("hello.txt")
.expect("hello.txt should be included in this project");
}
传播错误
传播(propagating)错误能更好的控制代码调用,因为比起你代码所拥有的上下文,调用者可能拥有更多信息或逻辑来决定应该如何处理错误
// src/main.rs
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
let username_file_result = File::open("hello.txt");
let mut username_file = match username_file_result {
Ok(file) => file,
Err(e) => return Err(e),
};
let mut username = String::new();
match username_file.read_to_string(&mut username) {
Ok(_) => Ok(username),
Err(e) => Err(e),
}
}
这种方式在 Rust 中很常见,因此也提供了一个语法糖:
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
let mut username_file = File::open("hello.txt")?;
let mut username = String::new();
username_file.read_to_string(&mut username)?;
Ok(username)
}
如果 Result 的值是 Ok,这个表达式将会返回 Ok 中的值而程序将继续执行。如果值是 Err,Err 将作为整个函数的返回值,就好像使用了 return 关键字一样,这样错误值就被传播给了调用者
? 运算符所使用的错误值被传递给了 from 函数,它定义于标准库的 From trait 中,其用来将错误从一种类型转换为另一种类型。
当 ? 运算符调用 from 函数时,收到的错误类型被转换为由当前函数返回类型所指定的错误类型。这在当函数返回单个错误类型来代表所有可能失败的方式时很有用,即使其可能会因很多种原因失败
还可以进一步简化:
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
let mut username = String::new();
File::open("hello.txt")?.read_to_string(&mut username)?;
Ok(username)
}
Attention需要注意的是,
?只适用于Result和Option两种情况,且两个不能一起使用,因为?不能自动对Result和Option进行转换